- 本教程适用于jetbrains全家桶开发工具(Pycharm、Idea、WebStorm、phpstorm、CLion、RubyMine、AppCode、DataGrid)
- 本教程适用于所有版本
- 软件直接从官网下载即可
- 不需要修改host
激活教程
1. 下载破解补丁
下载补丁文件:jetbrains-agent.jar
文件保存位置可以任意,建议放置到软件安装路径的bin目录下。避免误删文件。
下载补丁文件:jetbrains-agent.jar
文件保存位置可以任意,建议放置到软件安装路径的bin目录下。避免误删文件。
pika的持久化存储模块称为nemo存储引擎,其本质上是对rocksDB(只支持KV存储)的改造和封装。使其支持多数据结构的存储。
pika作为类redis数据库,所以肯定得兼容redis最基本的五种数据结构:string、hash、list、set、zset。

KV存储作为rocksDB原生支持的存储方式,所以并没有做太多的处理。仅仅只是在value的结尾加上8个字节的附加信息(前4个字节表示version,后4个字节表示ttl)。
version字段用于对该键值对进行标记,以便后续处理,如删除一个键值对时,可以在该version进行标记,后续再进行真正的删除,这样可以减少删除操作造成的服务阻塞时间。
对于每一个Hash结构,它都包含hash键(key)、域名(field)、值(value)。
nome的存储方式是将key和field组合成为一个新的key,将这个新生成的key与要存储的value组成最终落盘的kv键值对。
对于每一个hash键,nome还为它添加了一个存储元数据信息的落盘kv,它保存的是对应hash键下的所有域值对的个数。

上图表示nome对传统hash结构转换成kv结构的拆分存储模式。
GeoHash算法能够将二维的经纬度转换成字符串。主要有以下几个特性:
GeoHash将经纬度转换为hash字符串主要分为三步:
大概过程如下图,不断的对经纬度进行切割,直到精准度达到要求。
将经纬度转换成二进制编码
2
3
4
5
6
7
8
9
10
11
12
13
if (list.size() > (length - 1)) {
return;
}
double mid = (max + min) / 2;
if (value < mid) {
list.add('0');
convert(min, mid, value, list);
} else {
list.add('1');
convert(mid, max, value, list);
}
}
Redis4.0版本之后引入了memory usage命令和lazyfree机制。不管是对大key的发现,还是解决删除大key造成的阻塞问题都有了很大的提升。
memory usage的实现主要在object.c->memoryCommand方法中:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33{"memory",memoryCommand,-2,
"random read-only",
0,NULL,0,0,0,0,0,0},
else if (!strcasecmp(c->argv[1]->ptr,"usage") && c->argc >= 3) {
dictEntry *de;
long long samples = OBJ_COMPUTE_SIZE_DEF_SAMPLES;
for (int j = 3; j < c->argc; j++) {
if (!strcasecmp(c->argv[j]->ptr,"samples") &&
j+1 < c->argc)
{
if (getLongLongFromObjectOrReply(c,c->argv[j+1],&samples,NULL)
== C_ERR) return;
if (samples < 0) {
addReply(c,shared.syntaxerr);
return;
}
if (samples == 0) samples = LLONG_MAX;;
j++; /* skip option argument. */
} else {
addReply(c,shared.syntaxerr);
return;
}
}
if ((de = dictFind(c->db->dict,c->argv[2]->ptr)) == NULL) {
addReplyNull(c);
return;
}
size_t usage = objectComputeSize(dictGetVal(de),samples);
usage += sdsAllocSize(dictGetKey(de));
usage += sizeof(dictEntry);
addReplyLongLong(c,usage);
}
看到这个标题,你肯定在想:什么是雪崩?什么是穿透?什么是击穿?怎么感觉都是一个意思,都是缓存失效导致的数据库压力问题。
这三个问题的确都会导致数据库压力问题,但是出现的场景还是存在区别滴。在处理手段上也有很大的区别。
需要使用的热点数据都做了缓存,但是为了保证Redis的内存够用,所以会对一些数据进行设置过期时间操作。一般情况下存在定时任务去刷新缓存信息,这个时候就存在一个隐患的问题:假设在定时任务中设置的过期时间都一样,那么在某一个时间点时,大量的key同时过期。本来缓存抵挡住了大量的请求,key过期后,这些压力全部同时打到了数据库中,数据库可能就扛不住。直接被打挂了,重启数据库后,立马又被新的流量打挂了。这就是缓存雪崩。
(注:这里还有个隐患,Redis可能会频繁的处理过期key,从而导致Redis性能降低)
处理缓存雪崩主要有以下几个思路:
缓存穿透就是指客户端不断的查询缓存和数据库都没有的数据。相当于进行了两次无用的查询。降低缓存的命中率,增加数据库的压力。
解决手段:
缓存击穿和缓存雪崩有点像。但是又不一样,缓存雪崩是大面积的缓存同时失效,打崩了DB。而缓存击穿是指一个key非常热点,在不停的扛着大并发,当这个key失效的瞬间,持续的大并发就击穿缓存,直接请求数据库。
解决手段:
主要场景是多个线程同时去查询数据库的这条数据,那么我们可以在第一个查询数据的请求上使用一个 互斥锁来锁住它。
其他的线程走到这一步拿不到锁就等着,等第一个线程查询到了数据,然后做缓存。后面的线程进来发现已经有缓存了,就直接走缓存。
SpringTask是Spring自主研发的一个定时任务工具,不需要引入其他依赖就可以使用。
类似于shell中的crontab,只不过最前面多了一个Seconds秒级别。
Seconds Minutes Hours DayofMonth Month DayofWeek
| 时间元素 | 可出现的字符 | 数值范围 |
|---|---|---|
| Seconds | ,-*/ | 0-59 |
| Minutes | ,-*/ | 0-59 |
| Hours | ,-*/ | 0-23 |
| Day of Month | ,-*/?LW | 0-31 |
| Month | ,-*/ | 1-12 |
| Day of Week | ,-*/?L# | 1-7 |
在数组中选出一个元素做为中枢值,把所有比它小的元素都移动到它的左边,比它大的元素都移动到它的右边。直到数组有序。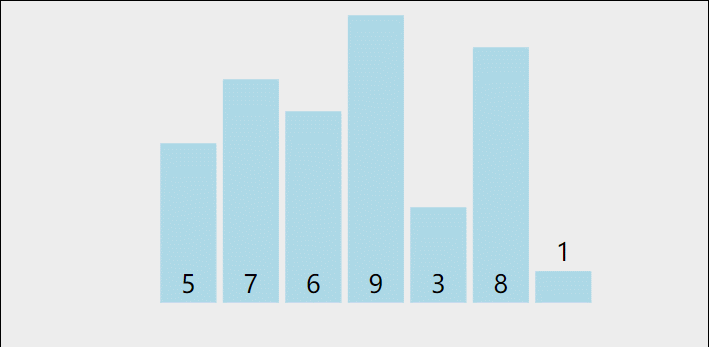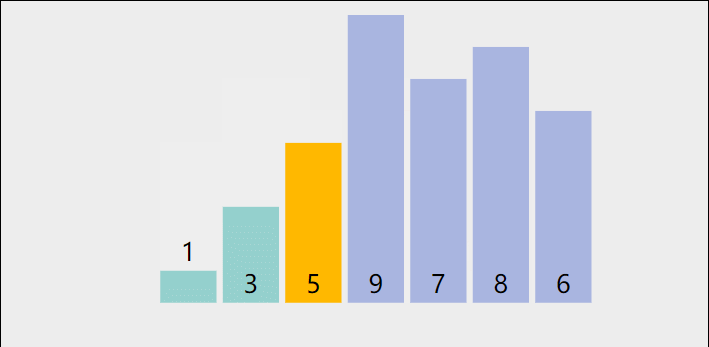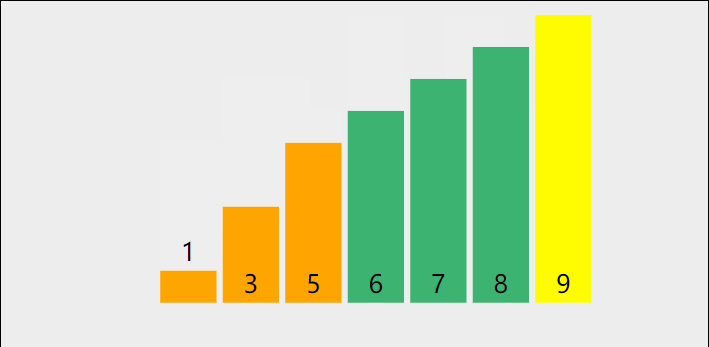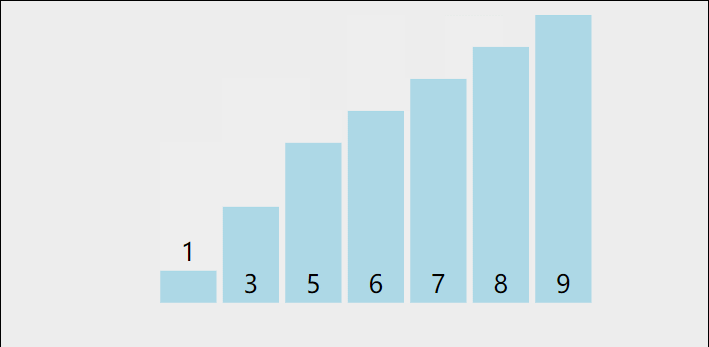
1 | private static void qSort(int[] a,int left,int right){ |
具体流程:
left和right代表两个初始化位置,分别表示需要排序数组的最左和最右。1 | // 非递归实现快排 |
对需要排序的数组的左指针和右指针l、r记录起来,压入到栈中,每次循环都会弹出一对l、r。
当栈为空时,说明都已经排序了。接收循环。
Linux自带排序命令:sort
在一些临时性排序需求的时候,使用该命令可以快速的处理。小巧的工具使我们使用非常便捷。
语法:sort [-bcCdfghiRMmnrsuVz] [-k field1[,field2]] [-S memsize] [-T dir] [-t char] [-o output] [file ...]
1 | -b 忽略每行前面开始出的空格字符。 |

